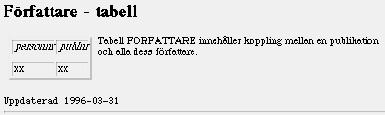
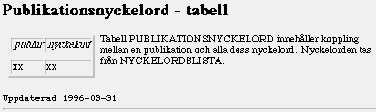
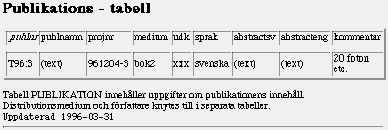
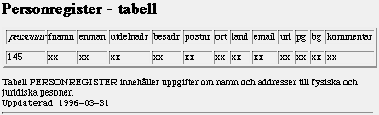
att databasförbindelsen stängs,
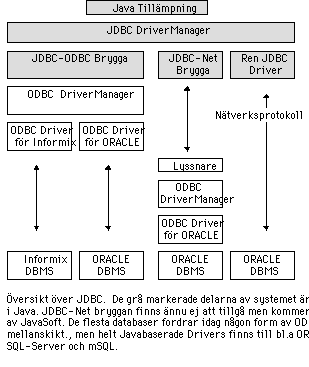
JDBC specifikationen innehåller ett dussintal klasser . Bland dessa
utgör klassen DriverManager huvudkomponenten. När man ansluter till
en databas håller DriverManagern reda på vilka JDBC-drivers som
finns. Detta kan den göra eftersom när en driver laddas in ska den
registrera sig hos DriverManagern. På detta sätt kan man göra
ett enhetligt gränssnitt mot olika databaser.
När man ska ansluta till en viss databas ger man DriverManagern en URL
till databasen samt eventuella användaridentiteter och lösenord.
DriverManagern utröner sedan vilka av de existerande JDBC-drivers som
skall användas för den i URL`en angivna databasen. När denna
väl har identifierats lämnar DriverManagern över kontrollen till
JDBS-drivern. Detta innebär att man minimerar overhead men också att
varje JDBC driver måste implementera klasserna -Statement som
används för att ställa SQL frågor och klassen ResultSet
som används för att hantera resultaten som SQL frågorna ger
samt båda klassernas felhantering.
De URL`er som används för att specificera databasen har syntaxen:
<protokollnamn>:<subprotokollnamn>:<subnamn>
Protokollnamnet är alltid jdbc. Subprotokollnamnet anger vilken typ av
databas-anslutnings mekanism (Driver) som skall användas. Sista delen av
URL syntaxen, subnamnet, beror av vilket subprotokoll som används men
pekar vanligen ut den dator där databasmotorn finns och vad databasen
heter.
Ett subprotokoll som kommer att vara vanligt till dess att det hunnit växa
upp en flora av JDBC drivers till de på marknaden förekommande
databasmotorerna är ODBC. Man skulle då kunna få en URL i stil
med:
URL`en använder en JDBC-ODBC brygga som möjliggör att man kan
använda databasmotorer till vilka det finns en ODBC driver men som det
ännu inte hunnit utvecklas någon jdbc driver till. Det finns dock
rena JDBC drivers till de flesta större databaser . Exempel på
sådana produkter är Weblogics Kona som innehåller JDBC-drivers
till bland annat ORACLE och Microsofts MS-SQL server.
En URL till en databas med en äkta jdbc driver kan till exempel se ut
så här:
jdbc:imsql:delphi.kstr.lth.se/adressregister
Denna URL hänvisar till databasen "adressregister" på en
mSQL-databas som kör på datorn delphi.kstr.lth.se via JDBC
subprotokollet imsql som i sin tur fordrar datornamn och databasnamn som
parametrar.
[top]
När man ansluter till en databas returnerar DriverManagern ett
Connection-objekt. När detta väl är skapat är det fritt
fram att ställa databasfrågor med hjälp av Statement objekt som
kan innehålla en sökfråga eller någon annan
begäran, t.ex. att radera poster till databasmotorn. Connection objekten
har även en annan viktig funktion, nämligen att hantera
transaktioner. Dessa kan hanteras på två sätt av jdbc:
- Auto-commit: Varje SQL fråga som ställs från ett statement
objekt behandlas som en transaktion.
- Normal-commit mode: alla SQL frågor som ställs blir del av en
transaktion som man kan göra commit eller rollback på som en helhet,
dvs en transaktion.
Det är fullt möjligt för en Applet eller en Java Applikation att
ha mer än en samtidig Connection till en eller flera databaser.
Moderna WWW-servers som Netscapes och Jeeves från JavaSoft har Servlet
APIer som gör det möjligt att enkelt generera WWW sidor med aktivt
innehåll. I kombination med JDBC är det mycket enkelt att skapa en
relationsdatabasanslutning. Denna anslutning sker alltså på
serversidan och innehåller lämpligen funktioner för t ex.
caching (lokal lagring) av databasfrågor samt deras resultat för att
öka systemets prestanda.
Om man använder en Applet för att visa data på klientsidan
är det även lämpligt att man här objektifierar
informationen som varje databasfråga ger upphov till innan den sänds
till klienten, antingen via något eget protokoll eller som ett
serialiserat objekt. På samma sätt delas objekt från klienten
upp i fält som kan matas in i databasen av detta serverprogram.
I WWW läsare vars javatolk baserar sig på JDK 1.02, sker
kommunikationen mellan klient Applet och databasinterface med hjälp av
TCP/IP och något för ändamålet lämpligt skapat
protokoll. (Vad som är lämpligt kan i detta fall avgöras av om
kommunikationen skall ske genom en brandvägg då man kanske
väljer att använda HTTP protokollet som man i de flesta fall lugnt
kan släppa igenom). I moderna WWW-klienter med stöd för JDK 1.1
kan man i stället använda distribuerade objekt där en del finns
på servern och en annan på klienten. Det blir sålunda
möjligt att skriva Appletfunktioner som direkt anropar objekt lagrade
på serversidan eller vice versa (RMI, Remote Method Invocation, se
exempelvis http://java.sun.com/products/jdk/1.1/docs/guide/rmi/).
En annan metod är att använda HTML-formulär på klientsidan
och låta det serverbaserade programmet fungera som ett konventionellt
cgi-program.
Fördelen med att använda Applets är att man kontinuerligt kan
ställa frågor till databasen och inte är hänvisad till ett
enda sändtillfälle då all information sänds över
från klienten till servern. Om man använder RMI-teknik är det
även möjligt att hålla reda på hur många
fönster man öppnat mot databasen. Detta gör att användaren
inte av misstag har flera fönster öppna samtidigt och på
så sätt kan riskera att föra in olika uppgifter i samma
fält och av misstag spara någon felaktighet. Arbetet med att
hålla rätt fönster aktiverat sköts lämpligen av ett
speciellt Javaobjekt designat för detta ändamål (Singleton
Pattern).
Nackdelen är att Appleten kan ta lång tid att ladda ned över
nätet. Lösningen med Applet passar alltså bäst om man inte
tvingas byta WWW sida allt för ofta.
[top]
WWW är ett medium som når över nationsgränser, det kan
därför vara ide att underlätta för läsarna genom att
hålla sidor på flera språk. Med hjälp av cgi-script
är det enkelt att automatiskt välja vilken sida som skall visas.
Naturligtvis skall det förutom cgi-scriptet finnas möjlighet att
välja vilket språk man vill läsa informationen på, om den
finns på flera språk.
En del WWW-klienter t.ex. Netscape ger användaren möjlighet att
välja vilket språk han föredrar. WWW-klienten kan då
på samma sätt som vad det gäller bilder och bildformat
förhandla med WWW-servern om vilket dokument som skall sändas ut till
klienten. Servern måste i detta fall konfigureras så att den
får information om vilka dokument som är på vilka språk.
Detta görs ofta med hjälp av pre- eller suffix för filer. Men
metoderna varierar från server till server och man gör bäst i
att läsa servermjukvarans bruksanvisning om man vill stödja dessa
funktioner.
Det första man behöver göra är naturligtvis att avgöra
vilka språk man behöver stödja och göra en kalkyl
över underhållskostnaderna i form av översättning av
nyproducerat material. I många fall räcker det dock inte med att
översätta texter man måste också ta med i
beräkningen att viss textinformation kan finnas inbakade i bilder vilket
innebär att man måste skaffa och underhålla bildmaterial
på de språk man beslutat att stödja.
Om man använder bilder med text som knappar i sitt
användargränssnitt måste man ta hänsyn till detta vid
designen av sidorna eftersom texten med största sannolikhet kommer att bli
olika lång på olika språk. Inte ens om man har textlösa
ikoner som knappar kommer man undan olika versioner för olika länder
eftersom människors associationsbanor varierar från land till
land.
Ett exempel på detta är att man i USA ofta har en parabolantenn som
symbol för nyheter. Detta fungerar eftersom amerikanen är van vid att
CNN sänder sina nyheter från hela världen på TV via
satellit. I mindre tekniskt utvecklade länder kan symbolen bli obegriplig.
Det är alltså viktigt att man väljer symboler med så
universell giltighet som möjligt för att bli förstådd och
för att inte av misstag väcka anstöt hos sina läsare.
För att säkerställa att man inte blir missförstådd
är det bäst att rådfråga infödda från de
länder som man riktar sig mot..
Så länge man håller sig till vanliga WWW dokument är
internationalisering oftast inget större problem så länge man
följer de ovan givna råden. Om man däremot producerar sidor av
mera interaktiv karaktär finns det ytterligare fallgropar att se upp
för.
För att göra det enklare för sig bör man skilja ut de delar
av ett program som kan behöva ändras vid internationalisering
så att de kan behandlas för sig. Det kan röra sig om
sorteringsalgoritmer, textens riktning m.m. Allt detta kan då man skriver
vanliga program lätt ordnas genom att sätta ställa in landet
vars språk du talar och låta operativsystemet ta hand om resten.
Men när det gäller WWW tillämpningar kan ju servern stå i
ett land och klienten befinna sig i ett annat.
Detta gör att man ofta måste skapa egna lösningar för
dessa problem. För det första måste man ta reda på var
klienten finns. Det kan man göra genom att titta på
environment-variablen REMOTE_HOST som anger hostnamnet (värddatorn)
där den anropande klienten kör.
Om WWW servern frågar DNS vem som har ett visst IP nummer kan man i denna
variabel få ut något i stil med delphi.kstr.lth.se där tecknen
efter sista punkten anger i vilket land klienten finns. Det finns idag undantag
med adresser som slutar på .com, .net och .org vilka kan finnas var som
helst i världen. Namngivning av IP-nummer kommer även att
förändras framöver.
Förutom att använda cgi-script för att avgöra från
vilket land läsaren kommer kan man även i någon mån
avgöra vem han är beroende på vilken domänadress anropet
kommer från, eller vilken typ av dator han använder.
[top]
[top]
I
jämförelse med icke datoriserade kommunikationstjänster finns
det många fördelar;
- först och främst vinner man tid,
- det blir enkelt att återanvända och modifiera material som man
kanske fått via elektronisk post annat digitalt medium,
- man kan göra information enkelt sökbar,
- informationen är enklare att tyda än handskrift,
- det krävs mindre fysisk lagringsutrymme
- informationen blir enklare att nå oavsett tid och rum.
Som synes finns det tungt vägande skäl att övergå till
helt elektronisk informationshantering. Vad man möjligen går miste
om är glädjen att få parfymerade brev, men förhoppningsvis
kan effektivare arbetsmetoder leda till att vi får mer fri tid över
till att skicka parfymerade brev till varandra och inte minst att odla
personliga kontakter på ort och ställe.
Det finns idag ett mångfald av nätlösningar som
fungerar bra inom den egna organisationen där man har god kontroll
över den hård- och mjukvara som används. Som exempel kan
nämnas Novell Netware och AppleTalk.
Dock blir det allt vanligare att man använder samma kommunikationsstandard
internt på ett intranet som på Internet. Detta har flera
fördelar.
- Man behöver inte lära sig olika program för att t.ex.
hämta en fil oavsett om den ligger lagrad på det interna
nätverket eller ej.
- De protokoll som har störst spridning på Internet är
plattformsoberoende. De är skapade för att användas i stora,
globala nätverk varför risken är liten att organisationen
växer ur systemet.
- Global samverkan blir enklare om en gemensam och välspridd standard
används
Trenden mot att använda Internetprotokoll för all kommunikation syns
inte minst på de stora operativsystemtillverkarnas ansträngningar
att sömnlöst integrera Internettjänster i sina
användargränssnitt (Windows 95 och Apples kommande system 8).
[top]
Liksom människor kommunicerar enligt olika conventioner och språk
kommunicerar datorsystem med varandra via protokoll. Protokoll finns för
att hantera olika typer av kommunikation exempelvis för att flytta filer
(ftp), kommunikation mot en inloggad terminal (telnet) och kommunikation i
World Wide Web (http).
[top]
De språk som används för kommunikation mellan datorer brukar
kallas protokoll. Det kan antingen vara mer eller mindre för
människor läsliga binära teckenkombinationer som sänds
över nätet. Som alltid gäller det att tala rätt språk
och fråga om rätt saker vid rätt tillfälle och rätt
plats. Till exempel lönar det sig föga att ringa Fröken UR
för att fråga om vädret. På samma sätt är det i
datorvärlden. Här anger man vem man vill kommunicera med m.h.a. ett
IP-nummer eller ett datornamn (som automatiskt översätts till
IP-nummer via en katalogtjänst DNS, Domain Name Server).
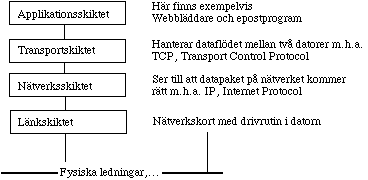
|
Figur 29 Principen för hur kommunikation sker mellan
datorer i nätverk med hjälp av TCP/IP protokollen. Ansvaret för
att alla datapaket kommer fram och i rätt ordning ligger i
transportskiktet.
|
Det räcker dock inte att ange vilken dator man ska till, man
måste även specificera vilken tjänst man vill komma åt.
Detta sker genom att man väljer ett så kallat portnummer. Varje
portnummer har en viss standardiserad tjänst. De fungerar med andra ord
som anknytningarna i en telefonväxel där IP numret är
växelns nummer och portarna är anknytningsnumren. Om man loggar in
på
en UNIX maskin kan man lätt ta reda på vilka portnummer som
står för vilka tjänster genom att läsa filen
/etc/services. Portnummer under 1024 är reserverade för systemets
bruk och får inte användas av vanliga användare.
Det program som anropar ett annat program brukar kallas klient och den anropade
för server därav namnet klient-server tillämpning.
[top]
Detta är förslag till nya standarder inom Internet området.
Oftast tar det mycket lång tid innan dessa standarder fastläggs av
IETF, Internet Engineering Task Force, och RFCerna blir därigenom de
fakto standarder för hur saker och ting fungerar.
Den som i detalj vill veta hur ett visst protokoll fungerar kan leta efter den
RFC som beskriver protokollen det är dock viktigt att titta på
bäst före datum som alltid finns angivet innan innehållet kan
tas för givet. RFCerna hittar man enklast genom att helt enkelt söka
efter RFC på Internet med hjälp av någon sökmaskin som
t.ex. Alta Vista. Många av de WWW-server-sites som håller RFCer har
sedan i sin tur ofta någon sökmotor som gör att man kan hitta
en viss RFC med hjälp av fritextsökning eller genom att söka
efter ett visst RFC nummer. Ofta är RFCerna dessutom hyperlänkade
till varandra. Se även lista över RFCs i
ftp://ftp.sunet.se/pub/Internet-documents/rfc/rfc-index.txt
[top]
FTP, File Transfer Protocol, används för att överföra filer
från en maskin till en annan oberoende av vilket operativsystem som
körs av de båda kommunicerande maskinerna (Postel & Reynolds,
1985).
Autentieringen av användare sker med hjälp av lösenord. Det
är möjligt att använda ftp för att sprida filer till
allmänheten genom att sätta upp så kallad anonym ftp. De som
vill hämta en fil identifierar sig då med användaridentiteten
"ftp" eller "anonymous" och som lösenord skriver han sin e-mailadress.
Ofta struntar ftp servern i om man anger en adress eller ej men det kan vara
bra att ange den. Den som hämtar filen kan då bli kontaktad av
serveradministratören t.ex. om det visat sig att den varit behäftad
med datorvirus.
Ibland får även anonyma användare lägga in filer i vissa
mappar/kataloger på ftp servern. När man skickar filer med
hjälp av ftp måste man tänka på om det är textfiler
eller binära filer och ge instruktioner därefter, eftersom
information hos binära filer annars kan gå förlorad.
Man bör dock tänka på att om vem som helst får lägga
filer så bör detta ske i särskilda mappar vars innehåll
inte är läsbart. Om så är fallet kan obehöriga
använda servern för att t ex distribuera piratkopior av program
Exempel på ftp session:
$ftp ftp.loopback.nowhere.com
user: per
password(per): ftp
Guest login OK
Welcome to loopback.nowhere.com you are user 12 of 120. All
transactions will be logged. If you find this unacceptable please sign off
now.
> ls
bin
etc
pub
> cd pub
> ls
junk
trash
usefulstuff
cd usefulstuff
> ls
README
goodFEMprogram.tar.gz
goodFEMprogram.solaris.bin.tar.gz
goodFEMprogram..win95.zip
gdpgm016.zip
> bin
binary mode set
> get gdpgm.zip
transfer completed. 6740543 Byte
[top]
HTTP, Hypertext Transport Protocol, användes för att i Word Wide Web
hantera filöverföring. Web-bläddrare som Netscape och Explorer
är HTTP klienter. WWW klienten använder HTTP för att hämta
och lämna information på en WWW-server. Förbindelsen mellan
klienten och servern är bara aktiv när meddelanden skickas och ingen
statusinformation lagras genom HTTP protokollets försorg.
WWW-dokumenten på Internet nås genom den så kallade URL,
Uniform Resource Locator, adressen. Exempel:
http://delphi.kstr.lth.se/swebu/index.html innebär att protokollet HTTP
skall användes för att hämta filen 'index.html' i filkatalogen
'swebu' på datorn 'delphi' som befinner sig vid avdelningen för
Bärande konstruktioners 'kstr' på LTH 'lth' i Internet domän
Sverige 'se'.
[top]
[top]
Simple
Mail Transfer Protocol är Internetstandarden för att sända
elektronisk post.(Klensin et.al., 1995).
Det vanligaste programmet för att hantera SMTP heter sendmail.
Ursprungligen kunde man bara sända text innehållande den amerikanska
teckenstandarden ANSI X3.4-1986. Ett flertal försök att finna metoder
att sända tecken som åäö har gjorts. De flesta dock
misslyckade på grund av att de gått ut på att byta ut
något tecken i det amerikanska teckenstandarden mot någon nationell
bokstav som t ex ett svenskt å. I och med införandet av MIME
(Borenstein & Freed, 1996b-f) har man nu lyckats komma runt problemet. MIME
standarden , Multipurpose Internet Mail Extension, används inte bara
för att få rätt bokstäver utan även för att ge
möjlighet att sända med bilder, ljud, video eller någon annan
form av data med elektronisk post.
[top]
POP står för Post Office Protocol (Myers & Rose, 1996). På
mindre datorer i Internet är det ofta opraktisk att använda SMTP
baserade program för posthantering, eftersom det skulle fordra allt
för mycket diskutrymme eller CPU kraft då de måste köras
kontinuerligt. Detta senare förhållande gör även att SMTP
baserade lösningar blir olämpliga för system som inte är
ständigt anslutna till nätet, som t.ex. bärbara datorer som
ansluter till nätet via modem. För att lösa dessa problem
skapades POP numera POP3 som gör det möjligt för en dator att
när den så önskar ansluta till en POP3 server och hämta
den post som samlats där. Servern i sig får oftast sin post via
SMTP. Vanliga program för att hantera POP3 är Popper på
serversidan och Netscape Navigator eller Eudora på klientsidan.
[top]
IMAP står för Interactive Message/Mail Access Protocol, (Chrispin,
1996g). IMAP Version 4, IMAP4, tillåter klienter att manipulera
elektronisk post lagrad på servern på liknande sätt som i
så kallade mailboxar på klient sidan. Protokollet gör det
även möjligt för en klient som ej varit ansluten till nätet
för längre eller kortare tid att synkronisera sitt innehåll med
servern.
IMAP4 innehåller funktioner för att skapa, ta bort och döpa om
mailboxar. Det är även möjligt att kolla om ny post anlänt,
ta bort meddelanden från servern för gott, söka i mail på
servern och selektivt hämta vissa meddelanden eller delar av dem.
Meddelandena på servern nås via meddelandets nummer. IMAP4 anger
inget sätt att posta elektronisk post. Postning sker lämpligen med
SMTP.
[top]
PPP står för Point to Point Protocol. Detta används för
att ansluta en dator till internet via en uppringd förbindelse, via t ex
ett modem. Tjänsten möjliggör såväl dynamisk som fast
IP nummer tilldelning till den uppringande klientdatorn. Med hjälp av PPP
kan man nå alla tjänster som är tillgängliga i ett normalt
Ethernet baserat TCP/IP nätverk.
[top]
[top]
Det
finns inga ofelbara system, men man kan redan vid designen av systemet undvika
de djupaste fallgroparna. Det kan röra sig om organiserade back-ups
(säkerhetskopior), gärna både automatiserade och centrala.
[top]
Man kan inte räkna med att alla alltid kommer i håg att ta back-up
på sina filer. Dessutom är det slöseri med tid, eftersom
användaren själv då måste hålla ordning på
media. Dock bör användaren se till att under arbetstiden göra
egna kopior på exempelvis textdokument man just arbetar med.
För att kunna använda back-up system måste man vara
säker på hur det fungerar och ATT det fungerar. Man bör med
andra ord prova på testsystem för att verifiera att det verkligen
fungerar och att man hanterar programmet på ett korrekt sätt. Detta
fodrar utbildning av den personal som skall hantera systemet. Det bli kostsamt
att utbilda hela personalen då man dessutom måste man utbilda
tillfälliga vikarier.
Av dessa skäl är det lämpligt att utse någon eller
några ansvariga för back-up funktionen. Säkerhetskopiorna
måste förvaras på lämpligt sätt så att de inte
förstörs vid brand eller slinker med vid ett inbrott. Till exempel en
inom räckhåll, en i brandsäkert skåp och en tredje i
annan byggnad.
När man lägger upp sin back-up strategi är det viktigt att man
tänker på hur långa driftstopp som verksamheten tål .
Det kan nämligen ta olika lång tid att restaurera systemet beroende
på hur säkerhetskopiorna gjorts. Ofta går det fortare att
återställa systemet från en total back-up än från
inkrementella back-ups. Detta skall vägas mot att det tar längre tid
att skapa en totalback-up än inkrementella dito.
[top]
Tillgängligheten är också beroende av tillförlitlig
hårdvara. De flesta elektronikkomponenter som t.ex. datorernas CPU- och
RAM-minnen åldras inte och har således lika stor sannolikhet att
vid varje given tidpunkt gå i sönder.
Förebyggande underhåll är alltså inte tillämpbart
som i fallet med mekaniska komponenter, som t.ex. hårddiskar, där
man kan förvänta sig en viss driftstid. Man kan istället
använda sig av redundanta system. Det kan röra sig om passiv eller
aktiv redundans. Vid passiv redundans fodras det manuella ingrepp för att
koppla in en ny komponent istället för den felande. Vid aktiv
redundans sker detta automatiskt. I de flesta fall räcker det med att man
har en extra dator att koppla in vid driftsbortfall. Systemet bör designas
så att denna operation är enkel att utföra. Till exempel genom
utbytbara eller externa hårddiskar istället för interna
så att verktygslådan inte behöva konsulteras.
Redundans kan också användas på system som har
förebyggande underhåll för hårddiskar etc. Man kan till
exempel byta enskilda hårddiskar i flykten i RAID 5 (Redundant Array of
Inexpensive Disks) system. Bäst är det om systemen kan konfigureras
att varsko administratören om eventuella fel innan användaren har
hunnit bli lidande. Det kan röra sig om att automatiskt till
administratören skicka ett e-mail som säger att en hårddisk
slutat fungera och systemet automatiskt har bytt till en reservdisk.
[top]
I det flesta system är det möjligt att ge användare
behörigheter att utföra vissa uppgifter, t.ex. att läsa
och/eller skriva i vissa filer eller att använda ett visst program.
Det är inte lämpligt att alla användare får göra
allting. Om så är fallet kommer man snart till ett läge
där det inte finns någon som har överblick över systemets
uppbyggnad och struktur. I förlängningen innebär detta att det
blir svårt att avgöra när det är dags för
systemuppgraderingar som t.ex. inköp av ny disk eller nätkoppling med
större bandbredd.
Det är således viktigt att man utser någon som har totalansvar
för systemet. Under denna person är det lämpligt att
fördela ansvarsområden som t.ex. skrivaradministratörer,
databasadministratör, nätansvarig m.fl.
Genom att skapa klart avgränsade ansvarsområden under en gemensam
ledning minskar man risken för dubbelarbete och missförstånd.
Om någon av dessa nyckelpersoner inte finns tillgängliga under
längre eller kortare tid blir kunskapsdomänen som en ersättare
behöver sättas in i mera avgränsad och han kan därigenom
snabbare komma in sin roll.
Man bör om möjligt även bygga systemet så att inte ens
nyckelpersonerna kan utföra den totalansvariges uppgifter. De bör
inte heller ha behörigheter att kunna ta över varandras uppgifter
utan den totalansvariges direkta medgivande genom en förändring av
behörighet i systemet. Om man inte följer dessa strikta regler kommer
förr eller senare någon att överskrida sina befogenheter,
må vara i bästa välmening, eller att det tillfälligtvis
var den bästa lösningen på något problem. Resultatet
på längre sikt blir dock oundvikligen kaos.
[top]
Om man i längden skall kunna vidmakthålla ett fungerande dynamiskt
system fordras det att man har egen kompetens, beställarkompetens,
som åtminstone är så stor att man vet vilka områden man
saknar och vet tillräckligt mycket för att kunna köpa in
rätt kompetens.
Att bygga ett system där målen inte från början är
klart definierade av beställaren kan få förödande effekter
såväl på systemets slutliga funktionalitet som på
leveranstiden. Ofta tenderar leverantörer av tjänster sälja det
de är bra på, och inte nödvändigtvis det som passar
situationen bäst. Vi vill här inte påstå att direkta
oärligheter är frekventa, men det fordras att konsulten har
tillräckligt stor överblick över på marknaden befintliga
system för att han ska kunna ge förslag på en bra lösning.
Vad som är en bra eller dålig lösning måste köpare
själv vara kapabel att avgöra.
Allra bäst är det naturligtvis om man själv tillfullo
behärskar sitt system. Detta kan naturligtvis ställa sig svårt
eftersom det fordrar ständig fortbildning om man vill bevara dynamiken i
systemet och utnyttja nya tekniska landvinningar.
[top]
[top]
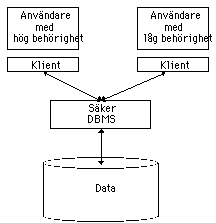
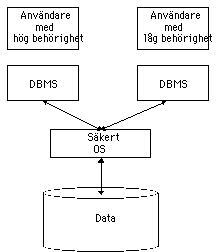
Vad
är det man behöver skydda? Man kan skydda:
- Hemliga data, affärshemligheter.
- Datas integritet, dvs förhindra obehöriga att göra
ändringar.
- Säkerställa den egna tillgången till data.
Ofta fokuserar man sina säkerhetssträvanden på att
förhindra att obehöriga kommer åt hemlig information t.ex. via
industrikontakter i samband med framtagning av nya produkter.
Även om man antar att det går att skilja på hemliga data och
publika data finns det all anledning att hantera problemen med dataintegritet
och tillgänglighet seriöst. Antag att data förstörs genom
ett intrång. Dessa kommer att behöva återskapas och bara
härigenom åsamka dig en kostnad. Ägnar du dig dessutom åt
någon informationstjänst blir förlusten så mycket
större. Andra mera svårgreppbara kostnader är förlust av
förtroende hos kunder, i detta fallet forskaren eller studenten,
investerare o.s.v.
Även om den som bryter sig in i systemet inte gör någon skada,
utan kanske bara lämnar meddelandet "Kilroy was here" måste man
verifiera att inkräktaren inte gjort något annat, detta kan ta
åtskilliga arbetsdagar i anspråk. Faktum är att en sådan
attack ofta är betydligt dyrare än de gånger data
totalförstörts, förutsatt att försvunnen information kan
hämtas från säkerhetskopia.
Det är emellertid inte bara en fråga om att skydda data och
information utan även ett företags eller privatpersons ansikte
utåt och goda rykte. Oftast har man under lång tid
investerat i att bygga upp en profil och gjort sig kända genom
varumärke och produktnamn. Dessa värden kan vara dyra att
ersätta.
Man skall inte driva uppbyggnad av de datorbaserade skyddsmekanismerna in
absurdum. Även om det kan vara svårt att erkänna kan mycket
väl risken att en anställd lämnar företaget med data
på en diskett och olovligen sprider dessa vara större än vad en
rimlig datasäkerhetsnivå kan erbjuda.
[top]
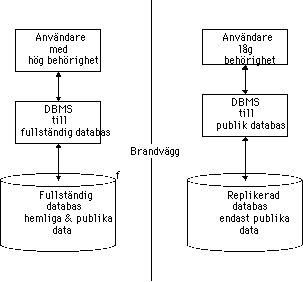
En brandvägg är en process som filtrerar all trafik mellan ett
skyddat säkert nät innanför muren och ett mera farofyllt
nät utanför, t.ex. Internet. Brandväggar kan delas in i tre
kategorier (Pfleger, 1996);
- screening routers,
- proxy gateways ibland kallade bastion hosts
- guards
De olika brandväggstyperna kan användas var för sig eller i
kombination. Typiskt för samtliga lösningar är att de utgör
ett skalförsvar som hindrar angripare utifrån. En brandvägg
skyddar bara data som finns innanför brandmuren och utgör
således inget skydd för data som transporteras över ett
osäkert nät.
För att stärka skyddet kan man använda kryptering. Det är
då lämpligt att krypteringen sker på maskiner innanför
den yttre brandväggen. På detta sätt minskar risken att en
inkräktare kommer åt krypteringsnycklar m.m. och systemet blir
säkrare. Med hjälp av kryptering och digitala signaturer som
säkerställer att innehållet inte har förändrats under
transport kan man på ett säkert sätt använda Internet
för kommunikation av känsligt material. Hur stark kryptografi som
behöver användas beror på hur länge informationen som
sänds är intressant för en angripare och hur stora resurser
potentiella angripare kan tänkas ställa upp med för att
dechiffrera meddelandena.
[top]
E Screening router är många gånger den enklaste och
effektivaste brandväggen. Datorer är vanligen anslutna till
nätet via en router. En router är en dator som tar emot digitala
informationspaket, konsulterar en routing tabell för att se var de ska ta
vägen, och skickar ut paketet mot sin destination på någon av
dess fysiska portar. En filtrerande router har två funktioner:
- Förhindra att falska interna adresser anropas
- Blockera kommunikation med valda protokoll i valfri riktning.
Den upprätthåller dessa funktioner genom att titta på IP
paketens headers. Dessa innehåller bl a käll- och
destinationsadress, paketlängd, och felkorrektionskoder.
[top]
Dessa har större komplexitet än routers. De ser inte bara headers och
protokoll utan tittar även på innehållet i de meddelanden som
skickas. Proxy gateway utgör en ställföreträdare som ges
uppgift att ta över en annan servers tjänster. Detta gör man
för att kunna lägga in ytterligare funktionalitet innan tjänsten
utföres på den ordinarie servern. Med en proxy gateway är det
t.ex. möjligt att se till att trafiken till port 25 (Standardporten
för SMTP) på en server bara består av giltiga mailmeddelanden
i mailprotokollet. Proxy servern får i det här fallet uppdraget att
sända iväg ett mail. Men före sändningen kontrolleras
mailet med avseende på exempelvis påhängda filer.
[top]
Har större komplexitet än proxy gateways och analyserar
innehållet på de meddelanden som sänds. Det kan till exempel
röra sig om att göra antivirus testning av e-mail.
[top]
[top]
Vid
ett intrång kan obehöriga komma in och använda systemet som
vore de behöriga användare. Man måste också tänka
på att en brandvägg inte alltid hjälper mot attacker.
Människor kan i värsta fall vara lättare att lura än
datorer. Vad gör systemadministratören då VD ringer och
säger att han skall visa den senaste produkten för företagets
viktigaste kund om två minuter och han säger sig ha glömt
lösenordet.
Det är inte omöjligt att tänka sig att
systemadministratören lämnar ut ett nytt lösenord i denna
stressade situation, utan att verifiera vem det egentligen var som ringde.
Detta gäller speciellt om den uppringande ger intryck av att känna
till sociala förhållanden och systemadministratörens namn
o.s.v.
Även om en brandvägg inte direkt kan förhindra en sådan
här attack kan den göra att det blir betydligt svårare att
nå uppgifter om sociala förhållanden och systemegenskaper som
till exempel IP-nummer. Om man inte vet vem man skall attackera
försvåras attacken avsevärt. En annan metod för att
försvåra attacker av denna typ är att använda
engångslösenord samt att förhindra inloggning från system
utanför den egna organisationen.
[top]
Man bör vidare föra loggbok över vem som använder systemet.
Loggen skall inte bara föras utan även kontrolleras, vilket även
det har sin kostnad i arbetstid. Ett medelstort system, med möjlighet till
telnet (protokoll för terminalemulering), ftp, mail och webtjänster,
kan ta en halv till en arbetsdag i veckan att kontrollera. Stora företag
som till exempel Sun har bevakning dygnet runt för säkerhetens
bevarande.
[top]
Ofta har datorlagrad information ett värde som kan göra att man vill
stjäla den. Antingen utgör informationen i sig en handelsvara och
har därigenom ett värde utanför den egna
informationsdomänen eller så kan den utgöra
bakgrundsinformation för annan inkomstbringande verksamhet.
Det säkraste sättet att skydda sig mot stöld är att
göra informationen oläslig för obehöriga genom kryptering.
Det är då viktigt att informationen är krypterad under hela
sitt liv, oavsett om den ligger fysiskt lagrad eller är under transport
över något datornät. Vanliga krypteringssystem på
Internet är PGP, som främst används för e-mail och SSL.
[top]
PGP, Pretty Good Privacy, är ett så kallat asymmetriskt
kryperingssystem som bygger på att den som vill ta emot krypterad
information lämnar ut sin publika nyckel till den som ska sända
informationen. Sändaren krypterar materialet med mottagarens publika
nyckel och skickar iväg det. Väl framme hos mottagaren kan
meddelandet dekrypteras med hjälp av mottagarens privata nyckel som bara
han känner. Se (Garfinkel, 1995)
[top]
Förkortningen SSL står för Secure Socket Layer. SSL, som
är Internets förhärskande säkerhetssystem,
möjliggör såväl identifiering av klienter och servers som
kryptering av överförd information. SSL används främst
för att sätta upp säkra HTTP förbindelser men kan även
användas t ex för ftp (filöverföring) eller telnet
(terminalemulering). Anledningen till att det är så enkelt att
anpassa till olika tjänster är att det i princip är vanliga
så kallade Berkeley sockets som modifierats för att tillåta
kryptering. En socket, sockel på svenska, utgör ett slags API
(Application Programming Interface) för TCP/IP nätverk.
SSL arbetar i två steg. I det första steget utbyter server och
klient information om varandra.
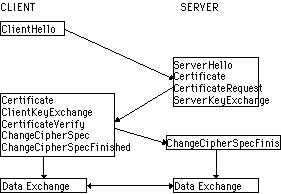
|
Figur 30 Bilden visar anrop på systemnivå av SSL
biblioteket. (Lindemalm, 1997)). Exempel på anrop är
ChangeCipherSpec vilket betyder Skifferutbytet klart (man har bytt
krypteringsnycklar).
|
I exemplet, enligt figur 30, vill CLIENT upprätta en krypterad
förbindelse med en server för att exempelvis sända känslig
information. Följande dialog utspinner mellan CLIENT och SERVER. Klienten
sänder ClientHello till servern som svarar med ServerHello. Dessa
meddelanden innehåller bland annat information om protokollversion,
krypterings- och kompressionsmetoder. I ett andra steg sänder servern sitt
certifikat till klienten. Eventuellt skickas ett ServerKeyExchange meddelande t
ex om servern saknar certifikat eller om det enbart är avsett för att
skapa signaturer. Om servern är autentierad kan den begära ett
certifikat från klienten. Autentiering sker idag via så kallade
certifikat (krypteringsnyckel) som utfärdas av olika kommersiella betrodda
organisationer som t.ex. Verysign (http://www.verysign.com). Det är
öven fullt möjligt att inom en organisation utfärda egna
certifikat. Huvudsaken är att de som skall använda certifikaten litar
på certifikatets utfärdare. Efterhand växer ett hierarkiskt
träd av förtroende upp.
På detta sätt kan man säkerställa att krypterade
förbindelser kan etableras i Internetmiljön.
[top]
Det finns olika möjligheter att blockera åtkomsten av ett system.
Det vanligaste och enklaste är att dränka systemet med information
så att kapaciteten inte räcker till för att släppa in
andra. Även om man inte direkt påverkar den tjänst man vill
blockera, låt oss anta att det är WWW-servern, kan man genom att
låta datorerna utföra andra resurskrävande tjänster
förhindra dem att hinna ta hand om WWW-tjänsten. Antingen genom att
datorkapaciteten tar slut eller att nätets kapacitet överskrids.
Detta kan ske genom att man exempelvis skickar gigantiska e-mail till
mailservern.
[top]
När man beslutar om en säkerhetsstrategi för en organisation
är det viktigt att alla inblandade får säga sin mening för
att de skall känna sig tillfreds med säkerhetssystemet. På
så sätt minskar risken att någon inom organisationen skapar
genvägar för sitt personliga arbete. Genvägar som kan
utgöra säkerhetsrisker. Till exempel sätter någon upp en
modemförbindelse till systemdelar som annars varit skyddade av en
brandvägg. Även externa faktorer påverkar valet av
säkerhetsstrategi (vad kräver eventuella samarbetspartners och
Riksrevisionsverket m fl ).
Man ska heller inte heller förlita sig på att man kan skydda sig mot
att en inkräktare tar sig in i systemet. Om han väl lyckas ta sig in
ska man se till att han kan göra så lite skada som möjligt,
t.ex. genom att man väljer behörigheter på lämpligt
sätt. I UNIX finns ett program som heter Cops (fritt tillgängligt
på Internet) som kan hjälpa systemadministratören med detta
arbete. En viktig princip är att aldrig ge användarna större
behörigheter än vad de absolut behöver. Det är t.ex.
vansinnigt att ge varje enskild användare systemets root-lösenord
bara för att de skall kunna stänga och starta om utskriftssystemet om
det skulle hänga sig. Eller att låta ett program köras som root
bara för det ska kunna skriva i någon viss skrivskyddad fil.
Under inkräktarens väg att nå viktiga systemfunktioner ska han
ha svårt att låta bli att röja sin existens. Till exempel
genom att man beräknar checksummor på filstorlekar så att det
syns om han t.ex. skulle lägga in en extra användare eller göra
någon annan oönskad filförändring. Detta kan på UNIX
system ske med ett program som heter Tripwire (fritt tillgängligt på
Internet).
Man kan även göra s.k. wrapper program. Detta är skal runt
program som kan utföra känsliga operationer i systemet. Innan den
verkliga funktionen utförs träder skalet in och kan t.ex. logga vem
som försökte utföra den. Det är vanligt att man
använder dessa s.k. wrappers runt TCP/IP funktioner som t.ex. ftp, telnet
m.fl. Förutom att logga händelser kan man förhindra
åtkomst på vissa tider av dygnet (t.ex. icke arbetstid). Det
är även möjligt att på detta sätt modifiera
mekanismer för start av vissa Internettjänster efter vem som
begär tjänsten.
Man bör även utarbeta system för att övervaka svarstider.
Förutom att dessa är bra att ha för att förutsäga
när man behöver utvidga systemet, kan sådan statistik
också ge fingervisningar om huruvida någon obehörig
använder systemet.
Även om man loggar vad som sker kan man tänka sig att en skicklig
inkräktare kan förstöra loggfilerna och därigenom
förhindra att hans identitet röjs. För att förhindra detta
kan det ibland, t.ex. om man misstänker ett pågående angrepp,
vara lämpligt att skriva ut loggen på en skrivare.
Det är också viktigt att man själv försöker bryta sig
in i systemet någon gång emellanåt för att se att det
inte uppstått några säkerhetsluckor. Ett lämpligt program
för att kontrollera säkerheten i UNIX system är Satan som liksom
Tripwire och Cops kan hämtas fritt på Internet.
Rent allmänt är det viktigt att man inte enbart har ett
skalförsvar utan även försvar på djupet. Man bör
även se till att systemets användare inte har för enkla
lösenord. Ett bra sätt att skapa lösenord som är
enkla att komma ihåg men svåra att knäcka, är att
välja en mening och ta första bokstaven i varje ord. Man bör
även se till att lösenorden innehåller några siffror
eller icke alfabetiska tecken. Ibland kan man använda dem
'onomatopoetiskt' för att kunna memorera dem enkelt. T.ex. memorera ordet
båten men skriv bå10.
De flesta system lagrar lösenorden i krypterad form. Dessa krypterade
lösenord skall naturligtvis inte vara tillgängliga för
allmänheten. För att förhindra att någon stjäl ett
lösenord och därigenom olovandes skaffar sig tillträde till
systemet, bör man kontrollera att man inte genom att kryptera en känd
ordlista bakvägen kan lista ut vad lösenorden är.
I UNIX-världen finns ett program, Crack (fritt tillgängligt på
Internet), som gör just detta. Det är all idé för
systemadministratörer att köra detta program på sina egna
lösenordsfiler med jämna mellanrum. Om något lösenord
skulle knäckas bör kontot omedelbart spärras och ägaren
underrättas så att han kan byta lösenord.
Man bör också tänka på att byta lösenord med
jämna mellanrum, systemet bör konfigureras så att det anmodar
användarna att göra detta. Man bör även byta lösenord
om man gjort en inloggning över en osäker, dvs icke krypterad kanal,
detta gäller speciellt lösenorden för
systemadministratörerna.
Det enklaste sättet att få ett säkert system är att skapa
en allmänt säkerhetsmedvetande, och en förståelse för
vad som är skyddsvärt i den egna organisationen. Detta
säkerhetstänkande bör genomsyra hela verksamheten och inte bara
datoranvändningen. Det kan röra sig om enkla saker som att instruera
medarbetarna att då de passerar en kodlåsförsedd dörr
tillsammans med en tillfällig gäst att slå några extra
siffror och avsluta med den riktiga, för att det skall bli svårare
att memorera koden. Eller en så enkel sak som att låsa sin
kontorsdörr när man ej är där, för att inte tala om
att aldrig lämna en dator i inloggat skick obevakad.
Det finns två vägar att gå då man bygger upp sin
säkerhetsstrategi
- Allt förbjudet - utom det som uttryckligen är tillåtet, figur
31,
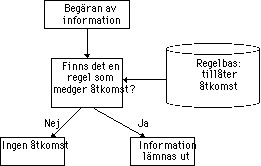
|
Figur 31. Man försöker här avgöra den minsta
mängd information som varje användare behöver för sitt
arbete och begränsar hans möjliga informationsåtkomst till
denna. Risken att man definierar denna minimala mängden alltför
snävt är uppenbar, och att man på så sätt gör
systemet onödigt svårarbetat.
|
- Allt tillåtet - utom det som uttryckligen är förbjudet, figur
32,
|
Figur 31. Här försöker man i stället dela
information så mycket som möjligt. Och gör bara
begränsningar om det är absolut nödvändigt. Denna typ av
strategier är lämpliga t.ex. för universitet och
forskningsinstitutioner där verksamheten i sig är mer eller mindre
publik
|
Hur man detekterar angrepp beror naturligtvis på vilken typ av system man
använder. Vanligtvis sker det genom följande metoder.
- Övervakning för att detektera oväntade förändringar
i systemets prestanda. Ofta det första tecknet som man märker.
Kan t.ex. bero på att någon försöker utnyttja datorn
för att knäcka lösenord.
- Övervakning av diverse loggfiler över hur systemet
utnyttjas. Till exempel varifrån ftp eller http anslutningar kommer.
Om man ser anslutningar som normalt inte skall kunna ansluta bör man bli
misstänksam. Än mera misstänksam bör man bli om dessa
anslutningar varar under längre tid än normalt. (Exempel på
logfiler som kan vara aktuella i ett UNIX system är messages, lastlog, ftp
och http loggar. Vad det gäller filen messages bör man även
kontrollera syslogd.conf så att en inkräktare ej ändrat vad
eller hur loggning sker)
- Övervakning av vem som använder systemet vid visa
tidpunkter. Om någon som normalt inte arbetar vid en viss tid
plötsligt och regelbundet är inloggad under denna kan man
misstänka att någon olovandes utnyttjar hans
användaridentitet.
- Genom den röra i systemet som inkräktaren ställer
till. Detta kan låta drastiskt men om röran inskränker sig till
brandväggsmaskinen och man har strikt övervakning (t.ex. genom
ovannämnda Tripwire på en UNIX-maskin) över denna så att
man hinner stoppa ett angrepp innan det når in i vitala delar av systemet
är det en bra metod.
- Leta efter saknade logfiler, eller poster i logfiler som borde
funnits där. Om delar av loggfiler är korrupta eller saknas kan man
misstänka att någon försökt sopa igen spåren efter
sin framfart.
- Leta efter processer som inte borde köra.
- Se om program för att övervaka systemet har modifierats.
T.ex. genom att beräkna MD5 (Schneier, 1996) checksummor på
programmen och jämföra dessa med checksummor som man vet är
korrekta. (Glöm inte att kolla checksumman på MD5 programmet)
- Kontrollera att behörigheter på viktiga filer inte
förändrats på otillbörligt sätt. (Till exempel
fått setuid-behörighet på ett UNIX-system)
Det finns ett flertal system för att automatisera och förenkla dessa
övervakningsuppgifter.
- Grips inte av panik.
En systemadministratör i paniktillstånd är en
säkerhetsrisk i sig.
- Dokumentera allt du gör och allt som händer i systemet.
När man upptäckt en attack är det första steget
att besluta om lämplig motåtgärd. Vilken denna blir beror
på om angriparen lyckats ta sig in i systemet, om så är fallet
är tillståndet akut oavsett om inkräktaren är aktiv eller
inte.
Misstänker man ett pågående inbrottsförsök bör
man handla omedelbart även om det inte är samma paniksituation. Anses
situationen allvarlig bör man bryta förbindelsen innan
inkräktaren lyckats ta sig in i systemet. Utifrån information
bör man så långt det går att spåra angriparen.
Även om man inte kan komma så långt att man vid en
rättegång kan få en fällande dom kan man ofta få
inkräktarens internetleverantör att sluta leverera
internettjänster till missdådaren.
[top]
Att via Internet hålla sig uppdaterad på de senaste metoderna att
utnyttja svagheter i systemen för att bryta sig in kan lätt bli ett
heltidsjobb för systemadministratören. Det finns dock ett par
organisationer listade nedan vars bulletiner och rekommendationer man bör
studera noga. De flesta av dessa är helt UNIX-orienterade. Anledning till
detta är dock troligen inte att UNIX skulle vara så mycket
osäkrare än t.ex. Windows NT utan snarare att det tar fyra fem
år innan man känner ett system så väl att man kan uttala
sig om huruvida det är säkert eller inte. Med tanke på att
Windows NT inte funnits så länge finns följaktligen inga
oberoende säkerhetsexperter att tillfråga. Man är utlämnad
till Microsofts egna experter.
[top]
Mailinglista som detaljerat behandlar svagheter hos diverse UNIX system.
Trafiken har ganska hög volym. För att prenumerera på listan
skicka ett mail innehållande "subscribe bugtraq" till listserv@netspace.org
[top]
Computer Emergency Response Team grundades 1989 av USAs
försvarsdepartement för att skydda Internets infrastruktur. Arbetet
bedrivs vid Carnegie-Mellon University i Pittsburg av ett dussintal
anställda som tar emot och analyserar rapporter från
Internetanvändare och utifrån dessa sammanställer och ger ut
varningar och rekommendationer om hur man höjer säkerheten. Deras
råd görs tillgängliga via newsgruppen comp.security.announce.
CERT har även en ftp-server där såväl varje
säkerhetsbulletin CERT givit ut som säkerhetsrelaterad programvara
kan hämtas. Adressen är ftp://info.cert.org. CERT kan
nås via e-mail på adressen cert@cert.org. CERT rekommenderar att
man krypterar sina brev. De stödjer kryptering enligt DES, PGP och PEM.
[top]
Computer Incident Advisory Capability group. Det amerikanska
energidepartementets datasäkerhetsorganisation. Håller ftp och http
server med säkerhetsrelaterade dokument och program. Adresser:
ftp://ciac.llnl.gov/pub/ciac/ , http://ciac.llnl.gov/,
mailto:ciac@llnl.gov
[top]
Computer Operations, Audit and Security Technology. Ett projekt vid Purdue
University, USA, för att höja nätverkssäkerheten. Har
förutom en intressant ftp/web site ett nyhetsbrev om
nätsäkerhetsfrågor. Adresser: ftp://coast.cs.purdue.edu,
http://www.cs.purdue.edu/coast/coast.html,
mailto:coast-reqest@cs.purdue.edu
[top]
När det gäller allmänna säkerhetsfrågor kan man
följa någon av grupperna;
comp.sercurity.annonce, comp.security.misc, alt.security samt
comp.security.unix den sistnämnda behandlar som namnet antyder
säkerhet i UNIX-nät men kan vara läsvärd för den som
sysslar med TCP/IP-baserade nät i största allmänhet.
När det gäller kryptografi finns följande intressanta grupper:
sci.crypt.comp security.pgp, comp.security.ripem, comp.protocols.kerberos
För frågor rörande brandväggar kan man vända sig till
comp.security.firewalls
[top]
[top]
En
server för WWW bruk består av ett antal komponenter som tillsammans
skapar den önskade funktionaliteten. Det rör sig om både
mjukvara och hårdvara. Kombinationen av dessa bestämmer serverns
egenskaper i olika avseenden, som t ex svarstider, driftsäkerhet,
framtidssäkerhet, utbyggbarhet inköpspris och driftskostnader. Detta
leder till en rad ibland motstridiga krav på systemet, som t ex snabba
svarstider, låga driftskostnader, stor driftsäkerhet och stor
datasäkerhet.
Eftersom användarnas förtroende för systemet till stor del
hänger samman med driftsäkerheten anser vi att denna bör
prioriteras högt i en utrustningsspecifikation. Vidare kan man
förvänta att man kommer att driva systemet under ett antal år
framåt varför det kan vara klokt i att försöka få en
uppfattning om de faktiska driftskostnaderna.
[top]
[top]
Vilken
databas som kan vara aktuell hänger starkt samman med vilket
operativsystem man väljer. Då vi av säkerhetsskäl
ansåg att Solaris (UNIX) var det bästa operativsystemet
koncentrerade vi våra studier på de databaser som var
tillgängliga på denna plattform.
Vi gjorde en del experiment med en shareware mjukvara, mSQL, som dock visade
sig sakna väsentliga funktioner. Det var bland annat inte möjligt att
köra nästade SQL frågor. Dessutom behandlar mSQL databasanropen
sekventiellt vilket skulle vara en nackdel ur prestandasynpunkt för ett
fleranvändarsystem. Inte heller fanns det något system för
låsning av poster. Om mSQL skulle ha använts hade ett sådant
system behövt simuleras med låsfiler ute i filsystemet, vilket i sin
tur hade lett till ett mindre robust system.
Även ur en annan prestandasynpunkt fann vi mSQL något tveksam. Vid
en JOIN av några få tabeller närmade sig prestanda de som man
får genom att hantera data som filer i filsystemet och använda UNIX
standardverktyg (cut, paste m.fl.) för att ställa samman data.
Ej heller hade mSQL några funktioner för att säkerställa
databasintegriteten. Våra tester gäller mSQL version 1.xx, på
senare tid har det kommit en ny version 2.0 (dock bara i beta ännu
så länge) som adresserar många av problemen, men fortfarande
kvarstår att anropen hanteras sekventiellt med prestandaproblem som
följd i ett växande fleranvändarsystem.
Ett annat alternativ som kommit på senare tid är den
svenskutvecklade mySQL som till skillnad från mSQL har en
multitrådad server vilket gör den mera lämpad för ett
fleranvändarsystem. Vi har inte gjort några egna
jämförande tester, men enligt användare som provat båda
är sökningen snabbare i mSQL om sökfrågorna är enkla.
När frågorna blir mera komplexa vinner mySQL. MySQL sägs
även vara långsammare att uppdatera än mSQL.
MySQL har även ett betydligt bättre system för att hantera
användare än mSQL. Till skillnad från mSQL där
behörigheter konfigureras i en fil, läggs användarna här i
en databas med tabeller för användare, databas och dator. Genom detta
förfarande kan man få bättre granularitet vid
säkerhetskonfigurationen i mySQL än i mSQL. Dessutom lagras
lösenorden i krypterad form i mySQL vilket ökar säkerheten. Vi
svenskar kan även glädja oss åt att mySQL kan konfigureras att
ge felmeddelanden på svenska.
Till såväl mSQL som mySQL finns jdbc drivrutiner av typ 4. Dvs helt
skrivna i Java och med kommunikation mot databasen över TCP/IP i
respektive databas eget kommunikationsprotokoll. mSQLs jdbc driver klarar
för närvarande bara Java version 1.02 med JDBC 1.1, medan mySQL
följer standarden för jdbc 1.22 vilket innebär att den fungerar
med java 1.1.
Både mSQL och mySQL har begränsningar vad det gäller
möjlighet att skapa prekompilerade SQL frågor och
transaktionshantering. För att få dessa funktioner måste man
gå till kommersiella system som t ex ORACLE eller Informix. Dessa system
utmärks av stora konfigurationsmöjligheter för olika
arbetsuppgifter. Detta leder dock till ökad komplexitet, ofta väl i
klass med fullödiga operativsystem som t ex UNIX eller VMS.
[top]
[top]
Den
information som ligger lagrad utanför databasen ute i filsystemet kan
göras sökbar med s.k. indexeringsmaskiner. Med hjälp av dessa
skapar man index över informationen som sedan används för att
göra snabba sökningar. Vi har erfarenhet av fem system: Excite
(http://www.excite.com), WAIS, Microsoft Indexserver som ingår i
Microsoft Windows NT 4.0 server paket samt Glimpse (fritt tillgängligt
på Internet) och Netscape (http://www.netscape.com).
WAIS utmärks tillsammans med Excite av att man kan använda hela
dokument som söknycklar. Resultaten från sökningarna
presenteras så att de mest troliga dokumenten visas först, så
kallad relevansrankning. Det går alldeles utmärkt att göra en
sökning och utifrån resultatet av denna fortsätta att söka
med de dokument som såg mest lovande ut som söknycklar.
Indexeringsprocessen i WAIS är dock mycket resurskrävande vad
gäller primärminne och diskaccess (skivminnesåtkomst). Det
är inga svårigheter att förbruka 100 MB primärminne
för att indexera några tiotal MB information. Indexen blir dessutom
stora, i samma storleksordning som den indexerade informationen.
WAIS indexen görs sedan tillgängliga över nätet via
speciella WAIS servers. Detta gör det möjligt att söka efter
information från flera WAIS källor samtidigt. Den stora
resursåtgången gör dock att WAIS idag används allt
mindre, en annan bidragande orsak är att de sökklienter som finns har
mindre intuitiva användargränssnitt . Källkoden till WAIS
systemet är fritt tillgänglig och kan fås att fungera på
de flesta UNIX system. Den är dessutom förberedd med hakar som
gör det möjligt att förse systemet med filter för att klara
olika dokumenttyper via ett API skrivet C++. I praktiken är det dock
svårt att dra nytta av detta då t.ex. filformatet för
kända ordbehandlingssystem ej är fritt tillgängliga utan
måste bestämmas genom "reverse engineering". Man kan dock tänka
sig att använda möjligheten för att skapa mallar för olika
typer av SGML (Standard General Markup Language) dokument beskrivningar som t
ex HTML
WAIS-systemet har i sitt grundutförande inga kopplingar så att det
direkt kan kopplas till en HTTP-server, utan man måste även
komplettera med dessa. Ett flertal mer eller mindre bra sådana program
vanligen skrivna i Perl finns att tillgå på Internet.
Excite (Excite Inc) är det söksystem som har bäst
användargränssnitt och levererar kan förutom sökresultat
även automatiskt skapa relevansrankade (precis som i WAIS) sammandrag av
de funna dokumenten. Sammandragen är mycket bra, ibland kan det vara
näst intill omöjligt att tro att de producerats på automatisk
väg. Excite är mycket tolerant mot stavfel i sökorden, och detta
är tur eftersom den inte klarar av att hantera icke amerikanska tecken som
å, å och ö. Det fungerar inte heller att indexera
HTML-dokument som innehåller så kallade umlaut-omskrivningar
för dessa tecken.
En väg att komma åt detta är att editera dokumenten och
ersätta alla umlaut-omskrivningar med standard ISO-Latin-1-tecken innan
dokumenten indexeras. Detta får emellertid till följd att de
automatiskt genererade sammanfattningarna kommer att sakna dessa tecken.
För att komma runt även detta kan man efter att dokumenten indexerats
återställa dokumenten så att våra svenska tecken
representeras av umlaut-teckenkombinationer. Vi har i vissa läge tvingats
utföra dessa operationer.
Excite klarar att hantera såväl text som HTML-dokument. Excite finns
för de större UNIX systemen som t.ex. Solaris samt till Windows NT.
Problemen med de svenska tecknen blir dock värre att lösa på
NT-plattformen då det där inte finns några standardverktyg
för automatisk editering av stora textmängder.
Programmet Glimpse utgör indexeringsmotorn i ett större system,
benämnt Harvest som kan användas för att skapa distribuerade
index över dokument spridda över nätet. Det fordras dock att de
servers som lagrar dokumenten kör Harvest programvaran så att de
olika delarna i systemet kan kommunicera med varandra. Harvest och Glimpse har
fritt tillgänglig källkod som fungerar på de flesta UNIX
system. Även Glimpse har problem med å, ä och ö. Dessa
problem löses på liknande sett som i Excite fallet. Precis som WAIS
måste Glimpse kompletteras med cgi-programvara för att fungera i
WWW-sammanhang.
[top]
Val av HTTP-server kan innebära val av mjukvara, men det kan också,
om man förväntar sig stor last på det färdiga systemet,
eller extremt hög drifts- och datasäkerhet innebära att man
låter webservervalet påverka hela systemarkitekturen. För att
öka driftsäkerheten kan man införa aktiv redundans i systemet.
Detta kan ske genom att man kör flera servermaskiner som via NFS (Network
File System, för montering av externa skivminnen över nätet)
delar en serverarea.
I SWEBU används en Netscape Enterprise 2.01 HTTP server. Fördelen med
denna är att den är lätt att såväl installera som att
administrera. Administrationen sker med ett WWW gränssnitt som är
mycket lätt att sköta. Dessutom finns bra hjälpfunktioner och
söksystem inbyggda i servern.
[top]
Operativsystemet är en av de viktigaste komponenterna för
såväl drift som datasäkerhet. Det bör ge möjlighet
att ge olika användare olika behörigheter vad det gäller att se
existensen av, läsa, skriva och exekvera filer. Systemet bör dessutom
vara väl inarbetat så att det går att hitta kompetenta
systemutvecklare och personer som står för drift och översyn
samt säkerhetsövervakning.
De flesta system är idag så komplexa att man bör ha sysslat med
systemet ett antal år innan man kan tillräckligt mycket för att
kunna veta hur säkerhetsläckor uppstår på det aktuella
systemet. Tänkbara System är idag olika varianter av UNIX, Open VMS
och med viss tvekan (på grund av dess korta tid på marknaden)
Windows NT.
[top]
UNIX är ett fleranvändarsystem, med fleruppdragskörning. UNIX
finns i ett flertal dialekter (de har dock inga svårigheter att
förstå varandra). Dels finns gratisvarianter som Linux och FreeBSD,
samt kommersiella som t.ex. Solaris från Sun. Det som skiljer mellan
gratisvarianterna och de kommersiella är att källkoden till systemen
är fritt tillgänglig i de förra vilket kan vara bra om man vill
göra någon ändring eller om man behöver göra egna
anpassningar t.ex. ett krypterande filsystem.
Nackdelen med de icke kommersiella systemen är att det är svårt
att ställa någon till ansvar om det inte fungerar enligt manualen.
Såväl Linux som FreeBSD håller idag mycket hög klass och
kan ur kvalitetssynpunkt mycket väl användas i kommersiella system
åtminstone så länge man håller sig på
Intelbaserade datorer. Linux finns även till andra arkitekturer men
är där betydligt mindre utprovat. Vad det gäller support finns
det idag flera företag som ägnar sig åt support för
Linux-system.
Fördelen med kommersiella system är att man kan fråga
tillverkaren om vilken hårdvara som fungerar. Ofta är även de
grafiska användargränssnitten bättre t ex med stöd för
Display Postscript och åtminstone runtime stöd för OSF-motif
program (Open Software Foundation). Ofta finns det grafiska
användargränssnitt för administration av allt ifrån
användare till konfiguration av RAID system (Redundant Array of
Inexpensive Disks, eller Redundant Array of Independent Disks. System av
många hårddiskar monterade i ett rack) och skrivare. Dessutom finns
det åtminstone om man väljer något av de mera kända
systemen mer färdigskriven och installationsklar kommersiell programvara
att tillgå än för de fria systemen.
Det i särklass vanligaste kommersiella UNIX-systemet är Solaris
från SunSoft (det tredje vanligaste operativsystemet efter Microsoft
Windows och MacOS). Solaris finns för SPARC, Intel och PowerPC
datorarkitekturerna. De olika versionerna är helt källkodskompatibla
med varandra varför det bara fordras en enkel omkompilering för att
skapa kod för en viss plattform. Systemet har mycket god
driftsäkerhet och har använts i en publik informationskiosk i ett
museum (Kulturen Lund) utan driftavbrott under mer än 24 månader.
På grund av den goda driftsäkerheten och det enkla handhavandet
valdes Solaris som bas för SWEBU projektet.
[top]
Open VMS var just i SWEBU fallet inte något alternativ då de
fordrade allt för kostbar hårdvara. För den som behöver
högpresterande system kan det dock vara värt att undersöka
närmare speciellt som det i VMS finns goda möjligheter att styra CPU
användning och eventuellt begränsa denna för vissa
användare eller procedurer så att de inte blockerar systemet
på grund av sitt höga personliga resursutnyttjande. VMS har
även ett mycket avancerat säkerhets och behörighetssystem. VMS
fordrar, i och med de större konfigureringsmöjligheterna, mer av
systemadministratören än UNIX och Windows NT. Få
tillgängliga programvaror för VMS är en annan nackdel med
systemet.
[top]
Fördelen med Microsofts Windows NT är att det har samma
användargränsnitt som Windows 95 och att den som har en Windows 95
utrustad PC på sitt skrivbord snabbt kommer igång med att köra
en NT server. Ibland kanske lite väl snabbt eftersom administration och
planering av fleranvändarsystem med avseende på t ex säkerhet
fordrar en hel del kunnande om säkerhet och nätverk. Mer än vad
som är vanligt bland persondatoranvändare i allmänhet. Detta
gör det faktum att man måste lära sig ett annat
användargränssnitt om man byter operativsystem försumbart i
jämförelse med de övriga kunskaper man måste skaffa sig.
Leverantören Microsoft, har kanske till följd att de nyligen slagit
sig in på marknaden för nätbaserade fleranvändarsystem,
inte riktigt insett de nya krav på säkerhet ett globalt nätverk
ställer. Vid flera tillfällen har allvarliga säkerhetsproblem i
Microsoft produkter förringats av leverantören och buggfixar har
låtit vänta på sig. Microsoft NT är dock ett embryo till
ett mycket bra operativsystem som vi kan förvänta oss mycket av i
framtiden.
[top]
Den viktigaste faktorn vid val av hårdvara för en WWW tjänst
som SWEBU bör vara driftsäkerheten. Detta innebär att man
bör välja datorutrustning som är uppbyggd av beprövade
komponenter. Om man väljer att köpa ett Intel/PC baserat system
bör man undvika märkesfabrikat som t ex IBM, Compaq med flera. Dessa
stora företag har stora resurser som de ofta utnyttjar för att skapa
egna företagsspecifika komponenter, som dels kan vara svåra att
få tag i som reservdel efter ett par år, och som dels kan vara
okända och därmed inte testade av mjukvaruproducenterna. Detta
resonemang gäller stationära datorer som är lämpliga som
WWW servers. Om man i stället talar om bärbara maskiner gör man
klokt i att välja en märkesprodukt, då dessa i vilket fall som
helst innehåller specialkomponenter och det då är bättre
att det är specialkomponenter från någon stor leverantör
än från en liten.
Man bör även se till att det finns någon som tar totalansvar
för försäljningen och designen av datorsystemet. Det är
annars mycket lätt (speciellt i PC världen) att man hamnar i
situationen att man köpt t ex ett nätverkskort från en
tillverkare och ett SCCI- kort från en annan samt minnen och moderkort
från en tredje. Om något skulle kringla i denna situation är
det vanligt att leverantörerna försöker kasta skulden på
varandra och man kan hamna i en knipa som kan vara svår, eller
åtminstone dyr, att ta sig ur.
Ofta är det svårt att förutse lasten på en WWW server
eftersom man i princip plötsligt kan få hela internet samhället
som besökare till sin server om den skulle visa sig innehålla
något av världsintresse. I de flesta fall är det inte
ekonomiskt försvarbart eller kanske inte ens möjligt att köpa
serverresurser som är designade att klara ett sådant värsta
fall.
En enkel Intel Pentium bestyckad dator räcker i de flesta fall. Den kan
serva tusentals WWW sidor om dagen utan att ge obehagligt långa
svarstider. De prestanda som fås beror naturligtvis till stor del
på vilket operativsystem som används.
Det är dock viktigt att man inte bara satsar på en snabb CPU (t ex
133 MHz Pentium) man måste även tänka på att välja
kringutrustning så att man får ett balanserat system. Detta
innebär idag på PC-sidan att man använder SCSI (Small Computer
System Interface) i stället för IDE (Integrated Drive Electronics)
som diskkontroller, åtminstone om man använder Windows NT eller UNIX
som operativsystem. Om man använder äldre Windows versioner
väljer man det som är billigast då operativsystemet
ändå ej kan utnyttja SCSI systemets större snabbhet. Det
bör dock tilläggas att SCSI systemet är lättare att bygga
ut med flera hårdiskar. Man kan ha upp till sex sju enheter anslutna till
samma SCSI kort.
Vad det gäller primärminne bör systemet utnyttja så snabba
minnen som möjligt. Man bör dessutom se till att man har
tillräckligt med minne för att inte behöva använda
virtuellt minne annat än vid absoluta toppbelastningar. För Windows
NT rekommenderas minst 64 Mbyte för att kunna hantera funktionaliteten som
beskrivs i denna rapport. UNIX klarar sig med något mindre mängd
minne. För Windows 95 med t.ex. Microsoft Access som databas bör det
räcka med ca 40 Mbyte.
Även det mest tillförlitliga system kan råka ut för
haverier t ex på grund av slitage av rörliga delar i skivminnen,
fläktar eller på grund av strömavbrott som i sin tur kan leda
till korrupta filsystem. För att minimera skadan av sådana
driftsavbrott bör man med jämna mellanrum ta säkerhetskopior av
information och programvara samt dess konfiguration som finns lagrat på
systemet. Detta görs lämpligen genom att man sparar
systeminnehållet på en bandstation.
Dessa säkerhetskopior kan vara inkrementella (man kopierar bara det som
ändrats sedan förra säkerhetskopian) eller totala (man kopierar
allt). Om man har allt för många inkrement blir det oftast
arbetsammare och mera tidskrävande att återställa ett skadat
system. Det är därför viktigt att anpassa bandstorleken så
att man inte får allt för många band att hålla reda
på när man tar en total säkerhetskopia. Lämpligen
väljer man en bandstation som använder DAT-band (Digital Audio Tape).
En sådan bandstation kan vanligen lagra mellan 2 och 5 Gbyte data
beroende på om komprimering används eller ej. När man
köper in band bör man välja band som är avsedda för
säkerhetskopiering av data och inte falla för frestelsen att
välja de billigare band som är avsedda för inspelning av ljud.
Dessa band är vanligen är av lägre kvalitet och kan
därigenom förorsaka förlust av data.
För våra experiment med SWEBU systemet använde vi en Sun 4 med
64 Mbyte primärminne, tre SCCI-2 Wide hårdiskar om vardera 1 Gbyte.
Denna maskin är bestyckad med en 110 MHz micro spark processor som vad det
gäller prestanda är i klass med en 200 MHz Pentium PRO processor
från Intel. Vårt val av hårdvara styrdes helt av
operativsystemvalet. Det visade sig dessutom att motsvarande PC system hade
blivit avsevärt dyrare. I och med valet av Sun/Solaris fick vi även
en leverantör av såväl hårdvara som operativsystem.
[top]
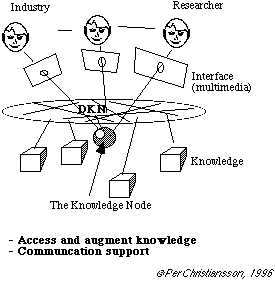
Rapporten beskriver hur vi i framtiden på Internet effektivt kan
kommunicera forskningsinformation. Det växande informationsflödet i
de globala nätverken gör det allt mera nödvändigt att skapa
kunskapsnoder där sakkunniga väljer ut och
kvalitetsmärker informationen samt förpackar den på
sådant sätt att den blir lätt att tillgodogöra sig
för de tänkta målgrupperna. I byggsammanhang bör man
över internet ha tillgång till forskningsresultat, byggnormer,
produkt-information, erfarenhetsdata från förvaltning etc., givetvis
innehållande hyperlänkade referenser till andra källor.
Nya möjligheter öppnas för användare att via anpassade
multimediala gränssnitt kommunicera mot underliggande information.
Allt mer av forskningsresultaten dokumenteras i digital form och blir
därmed mera tillgängliga. Samtidigt förändras
förpackning och tillhörande lagringsstrukturer som en följd av
introduktionen av avancerade IT-verktyg, som bland annat användes för
att hantera olika slags kunskapsrepresentationer i Internet-miljö
(objekt-, relationsdatabaser, bilder, etc.).
För att skapa förtroende för det nya mediet är det
viktigt att man beaktar de säkerhets-, sårbarhets och
integritetsaspekter som finns. Detta är särskilt viktigt eftersom
dagens IT tjänster bara är i början på en trolig framtida
utveckling och uppskalning där informationssökning, handel med
information, varor och tjänster kommer att ta en allt större del av
det dagliga livet.
Flera av de IT-verktyg som använts i projektet kommer att
förbättras inom de närmsta åren och därmed
ytterligare att öka systemets effektivitet och
användarvänlighet.. De modeller som tagits fram kommer
i stor utsträckning att kunna användas i senare skeden av
systemutvecklingen.
Vi kommer även att se agentbaserade system som utför
handlingar och interaktioner (som t.ex. byte av eller
försäljning/köp av information) med andra agenter eller
människor såväl inom begränsade intranet som på
Internet. Eftersom såväl den tekniska som den samhälleliga
förändringsprocessen kommer att påskyndas, och att
världen tack vare IT kan krympas, måste vi skapa verktyg som
gör det lätt för oss att ta fram nya lösningar som passar
den förändrade situationen.
Exempel på kritiska tekniksegment som fordras för att kunna
följa med i utvecklingen är:
- tillgång till snabba nätverk som t ex kan användas
för överföring av video, ljud och därigenom ge
möjlighet för rikare distansarbete och datorstött
samarbete eller för att snabbt få fram beslutsunderlag
från kvalitetsmärkta databaser världen över i ett
gigantiskt beslutstödssystem.
- bra krypterings- och autentiseringssystem för att kunna
bedriva handel och bevara personlig integritet
- att än mera fokusera på data- och
nätsäkerhet så att människor känner sig trygga
med den nya tekniken och verkligen vågar utnyttja den till fullo.
- platformsoberoende teknik (t ex Java baserade lösningar) för
att få ned utvecklingskostnaderna och få effektiv spridning bland
användarna. Effektiv spridning är viktig eftersom många av de
nya hjälpmedlen bygger på att man ska kommunicera med andra
människor eller maskiner. Som jämförelse kan nämnas
telefonen som inte blev riktigt användbar förrän den var
allmänt spridd.
- utveckling av de multimediala gränssnitten mot enskilda
användare och användare i grupp. Allt ifrån traditionell
multimedia till samarbete och visualisering i virtuella världar.
- avancerade IT-verktyg för att modellera och bygga
morgondagens informationssystem
Beställarkompetensen inom byggområdet måste generellt
höjas framöver för att öka sannolikheten för kloka och
långsiktiga IT investeringar kommer att ske. Denna rapport utgör en
inledning på ett sådant arbete med både en praktisk, exemplet
forskningsnod, och en mera teoretisk teknisk del. Vi har även
försökt att förmedla information för att öka
förståelsen för det hopvävda samband som råder
mellan våra tillämpningar och IT. Faktum är att vi nu
tillsammans till stora delar designar helt nya lösningar för hur
information med hjälp av avancerad IT effektiv skall kunna hanteras i
framtiden.
[top]
Borenstein N., Freed N., 1996b, Multipurpose Internet Mail Extensions (MIME)
Part One: Format of Internet Message Bodies, RFC 2045, Network Working Group
Borenstein N., Freed N., 1996c, Multipurpose Internet Mail Extensions (MIME)
Part Two: Media Types, RFC 2046, Network Working Group
Borenstein N., Freed N., 1996d, Multipurpose Internet Mail Extensions (MIME)
Part Three: Message Header Extensions for Non-ASCII Text, RFC 2047, Network
Working Group
Borenstein N., Freed N., 1996e, Multipurpose Internet Mail Extensions (MIME)
Part Four: Registration Procedures, RFC 2048, Network Working Group
Borenstein N., Freed N., 1996f, Multipurpose Internet Mail Extensions (MIME)
Part Five: Conformance Criteria and Examples, RFC 2049, Network Working Group
Christiansson P, 1996a, "Knowledge communication in the building
industry. The Knowledge Node Concept. "Construction on the Information Highway
Bled'96 Conference. June 1996, (12 pp). (Reviewed)
Christiansson P, Månsson B, Sörhede , (1992), "Ny
informationsteknologi Fastighetsförvaltning. Demonstrationsprojekt
Delphi". Lunds Tekniska Högskola, Bärande konstruktioner.
Byggforskningsrådet, Stockholm. (87 pp)
Christiansson P., 1995, "Svensk Byggforskning på Internet".
Tidskriften Byggforskning, nr. 6/95. (pp. 10-13).
Christiansson P., Engborg U., 1995, "PROJEKTRAPPORT 1 SWEBU, Swedish
Building Research on the World Wide Web den 5 april 1995". KBS-Media Lab, Lunds
Universitet. (6 pp.)
Christiansson P., Engborg U., Stjernfeldt F.,1996, "Skadeförebyggande
erfarenhetsuppföljning på Internet, SERFIN" Fastighetsnytt, 2:1996
(mars), Stockholm. (pp. 16-17)
Crispin M., 1996g, INTERNET MESSAGE ACCESS PROTOCOL - VERSION 4rev1, RFC 2060,
Networking Group
Garfinkel S., 1995, "PGP Pretty Good Privacy". O'Reilly & Associates, Inc.
Sepastopol, California. ISBN 1-56592-098-8. (393 pp).
Gunnarsson G., 1996, "Internet-boken. En beskrivning av Internet och intranet".
Pagina. Stockholm. (252 sidor.)
Gosling J, Arnold K, 1996, "The Java Programming Language". Addison Wesley.
(352 pp.).
HSV, 1997, "ASKen, Automatiska Studiekatalogen". Högskoleverket,
Sverige. http://asken.hsv.se/
http://www.ub2.lu.se/desire/index.html (kontrollerad 1997-05-18)
KBS-Media Lab, 1996, "KBS-Media Merkurius"
http://delphi.kstr.lth.se/kbs/projects/merkurius.html
KBS-Media Lab, 1997, "KBS-Media Lab, Lund University".
http://delphi.kstr.lth.se/
KBS-Media Lab, 1997a, "KBS-Media Lab: Swebu",
http://delphi.kstr.lth.se/kbs/projects/swebu.html. (1997-05-13).
KBS-Media Lab, 1997b, "SWEBU arbetsyta",
http://delphi.kstr.lth.se/swebu/arbetsyta (1997-05-13)
Klensin J., Freed, N. ,Rose M., Stefferud E., Crocker D. 1995, RFC 1869, STD
10, Network Working Group
Koch T, 1997, "DESIRE - Development of a European Service for Information on
Research and Education. Universitetsbiblioteket UB2, Lunds Universitet
(Traugott.Koch@ub2.lu.se)
Landin A, Hansson B, Berglund B, Modin J, Christiansson P, (1992),
"Kunskapsutveckling i Byggprocessen". LUTVDG/(TVBP-3032). (87 pp).
Lindemalm C, 1997, "Så här fungerar Netscapes SSL". Datateknik nr.
9, 15 maj 1997. (21 pp.).
Myers J, Rose M, 1996a, Post Office Protocol - Version 3, RFC 1939, STD 53,
Network Working Group
NCSTRL (1996), "Networked Computer Science Technical Reports Library"
http://www.ncstrl.org/.
Oracle, 1995, "PL/SQL User's Guide and Reference". Oracle Corporation, Redwood
City, California. (389 pp.)
Postel J., Reynolds J., 1985, File Transfer Protocol (FTP), RFC 959, Network
Working Group
Pfleeger C, 1996, Security in Computing, Prentice Hall, (pp 426-444)
Schneier B, 1996, Applied Cryptography, John Wiley & Sons (pp 436-441)
Groff R, Weinberg, 1994, Lan Times guide to SQL, McGraw-Hill (664 pp.)
Elmasri R, Navathe B, 1994, Fundamentals of Database Systems,(873 pp.)
Ousterhout J, 1994, Tcl and the Tk Toolkit, Addison-Wesley, (458 pp.)
Gamma E, Richard H, Johnsson R, Vlissides J, 1995, Design Patterns - Elements
of reusable software, Addison-Wesley (pp 127-134);
Wall L, Schwartz R, 1991, "Programming Perl", O`Reilly & Associates Inc, (
465 pp.)
W3C, 1997, "World Wide Web Consortium". http://www.w3.org/.